
Readable code is software code that is easy to understand and easy to change.
Unreadable code is a common complaint among software developers and one of the main contributors to technical debt. Abandoning unreadable code is one of the reasons engineers love to work on greenfield projects—there is no legacy code to deal with.
You’ve probably heard comments like, “It would take me longer to understand this code than to rewrite it from scratch.” This sentiment illustrates the problem with unreadable code: it slows down the development process.
Some engineers refer to readable code as “clean code.” In our opinion, “readable code” and “clean code” are synonymous, and the term “readable code” is easier to understand and, therefore, more “readable.”
Why is unreadable code a problem?
Although the “unreadable code” claim feels like a subjective opinion, it has a concrete business impact on software projects.
We want our code to be readable to speed up adding new features and bug fixes.
For example, we recently spent three hours figuring out how a feature worked, only to realize there was a documentation bug. Unfortunately, we made no improvements to make the code more readable, and the next developer will likely have the same problem. This next developer may be ourselves one year from now when we will have forgotten everything we learned about the feature.
Metrics for unreadable code
You can use several metrics to measure your code’s readability. The ideal metric would be the time it takes to understand the code, but this isn’t easy to measure. Instead, you can use the following proxies:
Time to fix a bug—Measure the time from when a developer starts working on a bug until the bug fix is ready for code review. Alternatively, measure the time from when a developer starts working on a bug until their first commit. A first commit is a good proxy for understanding the bug and starting to fix it.
Time to add a new feature—Measure the time from when a developer starts working on a new feature until it is ready for code review.
Time to onboard a new team member—Measure the time it takes for a new team member to make their first commit.
Code style violations—Measure the codebase’s number of code style violations. Code style violations can be measured using linters or static analysis tools. Some examples of code style violations relevant to readability are:
- Long functions
- Long files
- Deeply nested control structures
- Poorly named variables, such as 1-character variable names
Instead of measuring these style code violations, you can also enforce them in your CI pipeline. Most languages have
linters that update your code to match a standard style. For example, Go has gofmt.
How to make your codebase more readable
Readability is not a goal but a process. You can’t make your codebase readable overnight, but you can start making incremental improvements. Whenever you touch a piece of code, try to make it more readable.
Fix poor software structure
One pattern we see frequently is that the functionality of a core feature is spread across multiple software modules. The first problem this creates is that the software developer trying to understand the feature has to discover all the modules that implement the feature. Often, this requires grepping the codebase for key names – a tedious and error-prone process. The second problem is that the developer has to jump between files and directories to understand how the feature works, files that often have tons of other unrelated and distracting code.
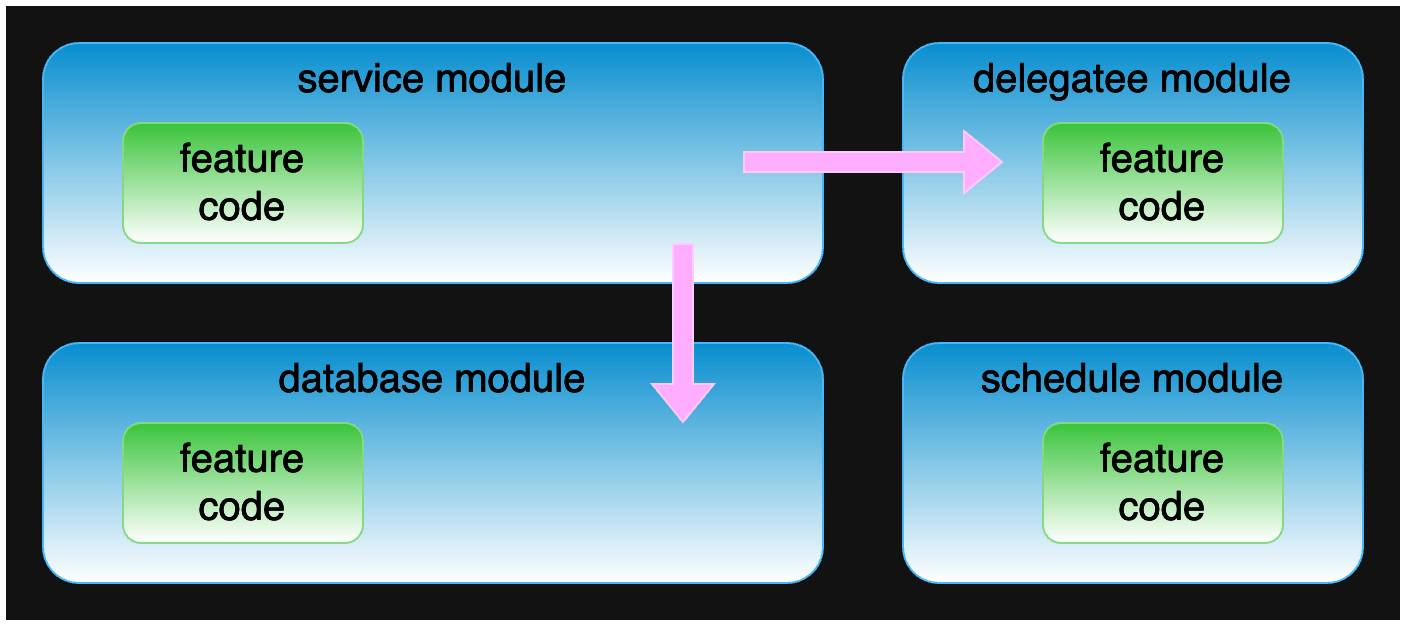
Hard to understand feature due to poor software design
Poor software structure often arises when we hurry to implement a feature and don’t consider future developers needing to make changes. This behavior is reactive software design—one developer reacts to the immediate need to implement a feature. Later, when implementing new features becomes almost impossible due to unreadable code, they react again by restructuring the code or rewriting old functionality from scratch. This process makes sense for prototypes or early products looking for product-market fit, but it is not sustainable for mature long-term software projects.
Often, developers may not be able to create a good software design when they start working on a new feature because they don’t understand all its ramifications. However, they should restructure their work before moving on to the next task—the best time to improve code is when you have all the context in your head.
We can restructure the above code example to move all the feature’s functionality into one or two modules. This reorganization makes it easier to understand the feature because we have to look at a much smaller number of files and are not distracted by unrelated code.
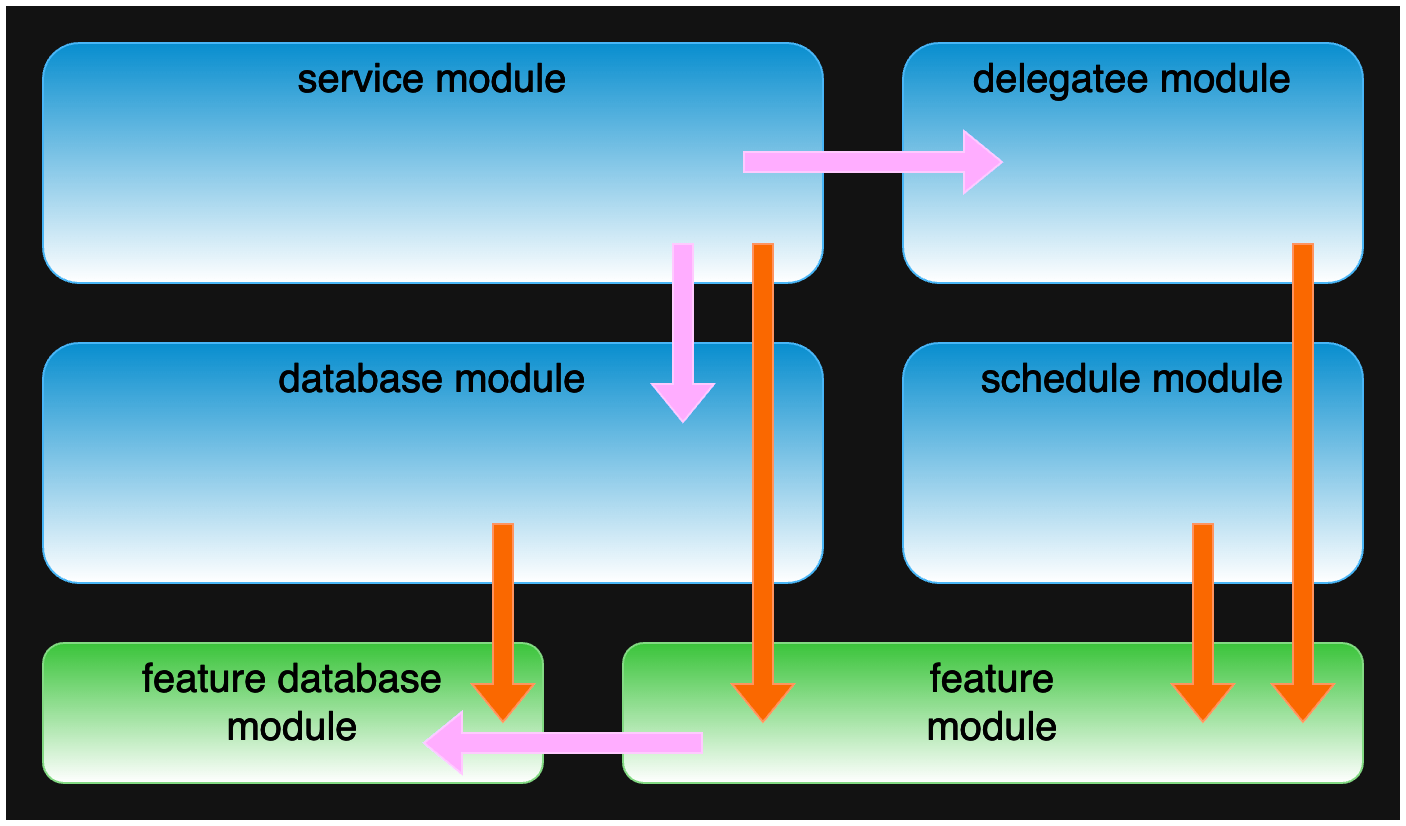
Easier to understand feature encapsulated in separate modules
Refactor local code for understanding
When entering a function, you should quickly understand what it does. The function code should be readable. If an engineer who first sees the function can’t understand it, it is too complex and should be refactored.
Long functions are difficult to understand because they require the developer to simultaneously keep a lot of information in their head. Oftentimes, the function presents implementation details to the developer before they can grasp the big picture. This process is cognitively demanding and error-prone.
Instead, we can refactor extended functions into smaller functions that each do one thing. This refactoring makes the code easier to understand because we can understand each small function in isolation. Hide complex logic in functions with descriptive names.
In addition, use descriptive names for variables. Good names make the code self-documenting and reduce the need for comments.
As an example of a function before and after refactoring, see this refactoring example gist. For a full explanation, you can jump to the refactoring section of the video below.
For more examples of common refactorings, see our article on top refactorings every software developer should know.
Use unit and integration tests
From a readability perspective, tests are a form of documentation. They show how the code is supposed to work. When reading a test, you can see how the code is supposed to behave in different scenarios.
Tests should also be readable. The same restructuring and refactoring principles apply to tests.
Another essential benefit of tests is that they allow developers to refactor code with confidence. When you refactor code, you can run the tests to ensure that the code still works as expected. Unfortunately, this means that when you want to make a change in legacy code without tests, you either have to write tests first or do a lot of manual testing to ensure that the code still works.
Useful comments
Comments should explain why the code is written the way it is, not what the code does. The code should be self-explanatory with descriptive variable and function names and encapsulated implementation details.
Sometimes, it is hard to tell the difference between “why” and “what,” so feel free to err on the side of commenting.
You can remove the comment if you renamed a variable or a function, and now the comment duplicates the code. One problem with comments is that they can get out of date, which is worse than no comments.
For example, before refactoring, you had this code:
// figure out which declarations we should not delete, and put those into keepNames list
keepNames := make([]string, 0, len(existingDecls)+len(fleetmdm.ListFleetReservedMacOSDeclarationNames()))
for _, p := range existingDecls {
if newP := incomingDecls[p.Name]; newP != nil {
keepNames = append(keepNames, p.Name)
}
}
keepNames = append(keepNames, fleetmdm.ListFleetReservedMacOSDeclarationNames()...)
After refactoring, the comment is a duplicate and no longer needed. It is even worse in this case because we renamed the variable, but the comment still refers to the old name. The comment is not only a duplicate but also misleading:
// figure out which declarations we should not delete, and put those into keepNames list
namesToKeep := namesOfDeclarationsToNotDelete(existingDecls, enrichedDeclarations)
Language features that make the code less readable
Some language features can make the code less readable. We will give an example from Go because we are familiar with Go, but the same principles apply to other languages.
Go nested functions
Go supports nested functions like this:
func outer(foo Foo, bar Bar) {
inner := func(item Item) {
// many lines
// ...
// of implementation details
}
// many lines
// ...
// of additional code
for _, i := range something {
inner(i)
}
// more code
// ...
return
}
Upon entering the function as a reader, the first thing you see is the inner function. The reader is presented with
specific implementation details before understanding the big picture. Instead, the reader should know where the nested
function is used before reading these implementation details.
One way to solve this issue is to forbid nested functions in your style guide. Always extract nested functions to the struct level or file level. However, this approach loses the benefits of closures and increases the number of functions at the struct/file level.
We hope that the Go team will improve the readability of nested functions in the future. For example, they could allow nested functions to be defined at the end of the function after the primary implementation:
func outer(foo Foo, bar Bar) {
// many lines
// ...
// of additional code
for _, i := range something {
inner(i)
}
// more code
// ...
return
// nested functions
func inner(item Item) {
// many lines
// ...
// of implementation details
}
}
Alternatively, IDE vendors can improve readability by entirely hiding nested functions by default.
Additional benefits of readable code
As you improve the readability of your code, you will notice several side effects:
- Many bugs will be easier to spot
- Other developers will be less likely to interrupt you with questions about your code
- If your code is open source, you may get more contributions
Make bigger improvements to your codebase with evolutionary architecture
In the following article, we discuss how to make bigger improvements to your codebase with evolutionary architecture.
Further reading
Why transparency beats everything else in engineering
How making work visible transforms teams from frustrated to high-performing through organizational transparency.My first conference talk experience
Lessons learned from presenting about readable code at a major software engineering conference.Build beautiful engineering dashboards—without paying a dime
Learn how to use GitHub, Grafana, and SQL to create powerful, drill-down metrics using only free tools.Key takeaways from literate programming
Discover how Donald Knuth’s literate programming principles can improve your code documentation practices.How to easily track engineering metrics with GitHub Actions and Google APIs
Build automated systems to measure and visualize your team’s engineering performance over time.Measuring and improving the execution time of Go tests
Optimize your test suite performance and reduce CI/CD pipeline duration with practical techniques.Top 3 issues with GitHub’s code review process
Understand the scalability and developer experience problems with GitHub’s default review workflow.Common use cases of AI for today’s software developers
Explore how AI tools can enhance productivity without replacing the need for readable, maintainable code.
Watch us discuss why readable code is important
Note: If you want to comment on this article, please do so on the YouTube video.