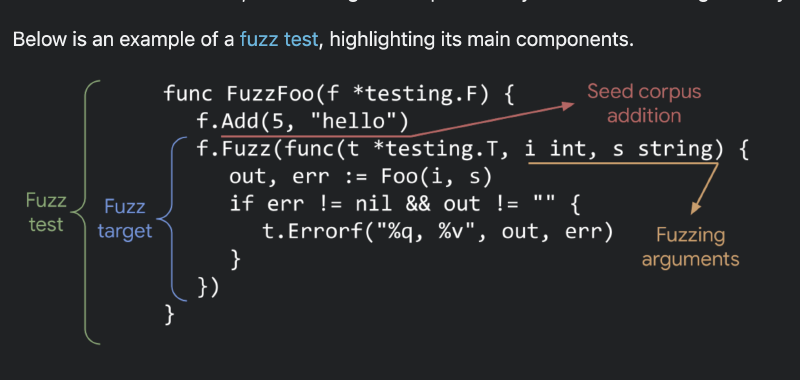
Fuzz testing is a software automated testing technique where random inputs are provided to the software under test. My background is in hardware verification, which uses sophisticated methodologies for pseudorandom testing, so I wanted to see what the Go library had to offer out of the box.
A Go fuzz test can run as:
- a normal unit test
- a test with fuzzing
A fuzz test is written similarly to a normal unit test in a *_test.go file, with the following changes. It must have a Fuzz prefix and use the testing.F struct instead of the usual testing.T struct.
func FuzzSample(f *testing.F) {
Here is a workflow for using fuzz testing. First, you create a fuzz test. Then, you run it with fuzzing to automatically find failing corner cases and make any fixes. Thirdly, you include the test and the corner cases in your continuous integration testing suite.
Create a fuzz test
When creating a fuzz test, you should provide a corpus of initial seed inputs. These are the inputs the test will use before applying randomization. Add the seed corpus with the Add method. For example:
f.Add(tc.Num, tc.Name)
f.Add(uint8(0), "")
The inputs to the Add method indicate which types will be fuzzed, and these types must match the subsequent call to the Fuzz method:
f.Fuzz(func(t *testing.T, num uint8, name string) {
The fuzz test can randomize any number of inputs, as long as they are one of the supported types.
Run the test with fuzzing
To run the test with fuzzing, use the -fuzz switch, like:
go test -fuzz FuzzSample
The test will continuously run on all your CPUs until it fails, or you kill it:
=== RUN FuzzSample
fuzz: elapsed: 0s, gathering baseline coverage: 0/11 completed
fuzz: elapsed: 0s, gathering baseline coverage: 11/11 completed, now fuzzing with 12 workers
fuzz: elapsed: 3s, execs: 432199 (144036/sec), new interesting: 0 (total: 11)
fuzz: elapsed: 6s, execs: 871147 (146328/sec), new interesting: 0 (total: 11)
A sample failure:
failure while testing seed corpus entry: FuzzSample/49232526a5eabbdc
fuzz: elapsed: 1s, gathering baseline coverage: 10/11 completed
--- FAIL: FuzzSample (1.03s)
--- FAIL: FuzzSample (0.00s)
fuzz_test.go:21: Found 0
The failures are automatically added to the seed corpus. The seed corpus includes the initial inputs that were added with the Add method as well as any new fails. These new seed corpus files are automatically created in the testdata/fuzz/Fuzz* directory. Sample contents of one such file:
go test fuzz v1
byte('\x01')
string("0a0000")
Adding the failure to the seed corpus means that the failing case will always run when this test is run again as a unit test or with fuzzing.
Now, you must fix the failing test and continue the loop of fuzzing and fixing.
Include the test in continuous integration
When checking in the test to your repository, you must either include the testdata/fuzz/Fuzz* files or convert those files into individual Add method calls in your test. Once the test is checked in, all the inputs in the seed corpus will run as part of the standard Go unit test flow.
Initial impressions
Fuzz testing appears to be a good approach to help the development of small functions with limited scope. The library documentation mentions the following about the function under test:
This function should be fast and deterministic, and its behavior should not depend on shared state.
I plan to give fuzzing a try the next time I develop such a function. I will share the results on this blog.
Concerns and Issues
Native fuzzing support was added to Go in 1.18 and seems like a good initial approach. However, it feels limited in features and usability. The types of functions, fast and deterministic, that fuzzing is intended for are generally not very interesting when testing real applications. They are good examples for students learning how to code. However, more interesting testing scenarios include:
- Functions accessing remote resources in parallel, such as APIs or databases
- Functions with asynchronous code
Secondly, the fuzzing library does not provide a good way to guide the randomization of inputs and does not give feedback about the input state space already covered. It does provide line coverage information, but that doesn’t help for unknown corner cases.
If one of my inputs is intended to be a percentage, then I want most of the fuzzing to concentrate on the legal range of 0-100, as opposed to all numbers. This lack of constraints becomes a problem when adding additional inputs to the fuzzing function, as the available state space of inputs expands exponentially. If the state space of inputs is huge, there is no guarantee that fuzzing accomplished its goal of finding all corner cases, leaving the developer with a false sense of confidence in their code.
Lastly, the fuzz test is hard to maintain. The seed corpus is stored in files without any context regarding what corner case each seed is hitting. Software engineers unfamiliar with fuzz testing will find this extremely confusing. If the fuzz test needs to be extended in the future with additional inputs or different types, the old seed corpus will become useless. It will be worse than useless – the test will not run, and the developer unfamiliar with fuzz testing will not have a clear idea why.
fuzz_test.go:16: wrong number of values in corpus entry: 2, want 3
That said, understanding the fuzz testing limitation, I’m willing to try fuzz testing for more interesting test cases, such as database accesses. I will report my findings in a future post.
GitHub gist:
Further reading
- Benchmarking performance with Go
- Measure Go test execution time
- Speed up Go CI tests by breaking them apart.
- Unit testing a Chrome Extension
Go fuzz testing video
Note: If you want to comment on this article, please do so on the YouTube video.